TensorFlow alapozó
TensorFlow alapozó
(neurális hálózatok, tenzorok és képfelismerés a gyakorlatban)
Napjaink egyik legnépszerűbb témája a mesterséges intelligencia és a gépi tanulás. Akit mélyebben érdekel ez a terület, az előbb-utóbb bele fog futni a TensorFlow-ba ami a Google mesterséges intelligencia megoldáscsomagja. A programkönyvtár segítségével például olyan nyalánkságokat fejleszthetünk, mint a konvolúciós mély neurális hálóztok (Convolutional Deep Neural Networks), amik a tárgyakat képeken felismerni képes rendszerek lelkét képezik. Ez az írás egy kis alapozó azok számára, akik TensorFlow-val szeretnének foglalkozni. Az írás második felében szeretném majd egy rövid példán keresztül bemutatni, hogy hogyan működik a rendszer a gyakorlatban, így annak megértéséhez alap Python tudásra lehet majd szükség. Az írás többi része alap programozó tudással (vagy akár anélkül is) értelmezhető.
Vágjunk is bele a közepébe. Elsőként érdemes tisztázni, hogy mit jelent a tenzor (tensor) a TensorFlow-ban. Ráment pár órám, hogy értelmezni próbáljam a tenzor fogalmát a fellelhető matematikai definíciók alapján. Végül úgy döntöttem, jobban járok ha megnézek pár TensorFlow-s kódot. Ekkor kellett rádöbbennem, hogy a tenzor nem más mint egy tömb. Szinte hallom a távolban ahogy a fizikusok és matematikusok felszisszennek erre a definícióra, mondván hogy a tömb maximum a tenzor reprezentációja, nem a tenzor maga, de a lényegen ez sokat nem változtat. Van 1 dimenziós tenzor (számok listája), amit vektor néven is szoktunk emlegetni, van 2 dimenziós tenzor (számok listájának listája), amit mátrixnak is szoktunk hívni, és persze a tenzor lehet 3 vagy több dimenziós is (számok listájának listájának listája, stb.). A TensorFlow segítségével gráfokat építhetünk aminek minden csomópontja egy tenzor transzformáció. Ezt a gráfot hívjuk modellnek. A legtöbb esetben a modell egy sima szekvenciális gráf, tehát olyan mint egy cső amibe egyik oldalon betolunk egy tenzort, a csőben végigmegy pár transzformáción, a végén pedig a transzformációk eredményeként kijön egy másik tenzor. A transzformációs gráfon tehát tenzorok “folynak” végig, innen származik a TensorFlow név, ami tenzor folyamot jelent.
Szép-szép ez a tenzor folyam dolog, de hogy lesz ebből mesterséges intelligencia és neurális hálózat? Vegyünk egy egyszerű példát: Egy olyan neurális hálózatot, ami eldönti, hogy egy képen kutya vagy cica látható. A hálózat bemenete egy kép, ami leképezhető egy 3 dimenziós tenzorra, aminek az egyik dimenziója a szélesség, a másik a magasság, a harmadik pedig az egyes szín összetevők. Egy 32x32 pixeles RGB kép például egy 32x32x3 méretű tenzorral (tömbbel) írható le. Ha a kép szürkeárnyalatos lenne, akkor elég lenne egy 32x32-es mátrix (32x32x1). Ez lesz tehát a modell bemenete. A kimenet egy 2 elemű vektor (1 dimenziós tenzor), ahol mindkét elem egy valós szám 0–1-ig. Az első szám azt mondja meg, hogy a képen látható dolog mennyire cica, a másik pedig hogy mennyire kutya (mennyire tartozik a cica vagy a kutya osztályba). A cicákat és kutyákat felismerő neurális hálózatunk tehát felfogható egy doboznak ami tenzor transzformációkat tartalmaz és egy 3d-s tenzort képez le 1d-s tenzorrá. Hasonló doboz például egy arcfelismerő rendszer is. A bemenet itt is egy 3d-s tenzor, a kimenet pedig egy vektor (1d-s tenzor). Itt általában annyi a különbség, hogy a kimeneti vektor egy fix méretű (pl. 256 elem) tulajdonság vektor (feature vector). A cicás/kutyás példával ellentétben itt nem tudjuk, hogy a vektor egyes elemei mit jelentenek, csak annyit tudunk, hogy ezek jellemzőek az adott arcra. Ha fel akarunk ismertetni egy betanított arcot, akkor a hálózattal elkészítjük a feature vectort, majd összehasonlítjuk az adatbázisunkban lévő más feature vectorokkal. Ha találunk olyan vektort ami bizonyos hibahatáron belül hasonlít a minta vektorhoz, akkor megvan a keresett arc. Minden egyes neurális hálózat felfogható olyan dobozként, aminek a bemenete egy tenzor, a kimenete pedig egy másik tenzor. A kérdés már csak az, hogy mi van a dobozban?
Egy neurális hálózat a nevéből adódóan mesterséges neuronok hálózata. Egy mesterséges neuron a következőképpen néz ki:
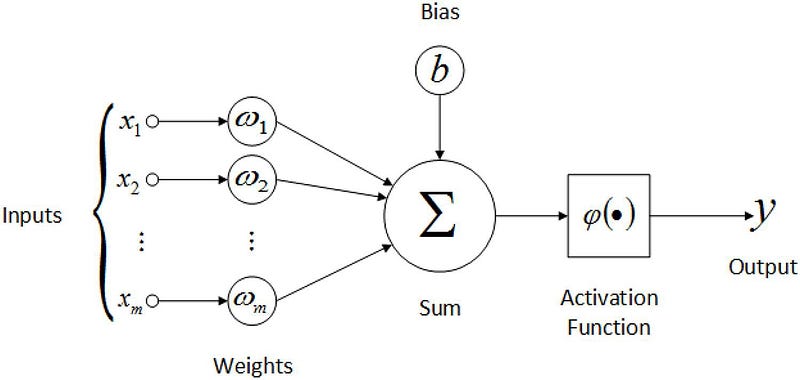
A neuronnak súlyozott bemenetei vannak, ami annyit jelent, hogy minden bemeneti értéket megszorzunk egy w számmal (az első x1 bemenet w1-el, a második x2 bemenet w2-vel, stb.). A neuron ezeket a bemeneteket összegzi, ehhez jön még egy bemenetektől független módosító (bias), majd egy kimeneti függvényen (aktivációs függvény) keresztül előáll a neuron kimenete. A neurális hálózat ilyen neuronok hálózata.

A hálózatnak van tehát X db bemenete, ezt követi egy vagy több rejtett réteg, majd egy utolsó réteg, ami a kimenetet adja. Egy ilyen hálózatot a súlyok (a bemenetet szorzó w értékek) állítgatásával lehet paraméterezni és megvalósítható vele bármilyen logikai függvény, sőt, ha megengedett a visszacsatolás, úgy a neurális háló lehet Turing-teljes. Ez utóbbi azt jelenti, hogy bármilyen létező algoritmus (program) leképezhető neurális hálózattal. Elképzelhetjük ezt úgy is mint egy dobozt, aminek van bizonyos számú be és kimenete, valamint van rajta egy csomó csavargatható potméter. A potméterek megfelelő beállításával bármilyen program létrehozható. Eddig persze nem annyira érdekes a dolog, hiszen egy függvényt, vagy egy algoritmust egyszerűbb leprogramozni mint potméterek beállítgatásával megadni. A varázslat abban rejlik, hogy a potmétereket nem nekünk kell kézzel becsavargatni ugyanis ezt megoldja helyettünk a tanítási algoritmus. A mi feladatunk csak annyi, hogy elég mintát (tehát bemenetet és hozzá tartozó elvárt kimenetet) adjunk a rendszernek. A tanító algoritmus minden egyes mintát átfuttat a neurális hálózaton, majd összehasonlítja a kimenetet az elvárt kimenettel. Az eltérések alapján beállítja a potmétereket, majd fix lépésben ismétli a folyamatot, vagy addig, amíg a kimenet és az elvárt kimenetek közti hiba egy adott hibahatár alá kerül. Pont ugyanúgy hangolgatja a hálózatot mint a hangmérnökök a potmétereket a megfelelő hangzás érdekében. Ez jól láthatóan egy hagyományostól eltérő programozási paradigma, hiszen míg hagyományos esetben a programot egy programozó írja, addig itt egy rendszer hozza létre a minták alapján. Az így létrejött programok működését komplexitásuk miatt képtelenség átlátni, de ennek ellenére működnek. Olyan programokat tudunk tehát létrehozni, amiket amúgy képtelenek lennénk megírni és ez az ami miatt olyan izgalmas a mesterséges intelligencia. Ehhez viszont nagyon sok minta kell. Nem csoda hát, hogy a mesterséges intelligencia és a bigdata kéz a kézben járnak. Bigdata nélkül ugyanis nincs jó MI.
Mielőtt fejest ugranánk a kódolásba, még egy témáról szerettem volna írni, ez pedig a konvolúciós hálózatok témája. A konvolúciós neurális hálózat olyan neurális hálózat, ami tartalmaz konvolúciós réteget. A konvolúció a képfeldolgozásból lehet ismerős. Arról van szó, hogy létrehozunk egy kis “alhálózatot”, aminek a bemenete egy X*X méretű mátrix, és ezt a kis alhálózatot ismételgetjük meg a bemeneti mátrixon 1 vagy több pixellel eltolva.
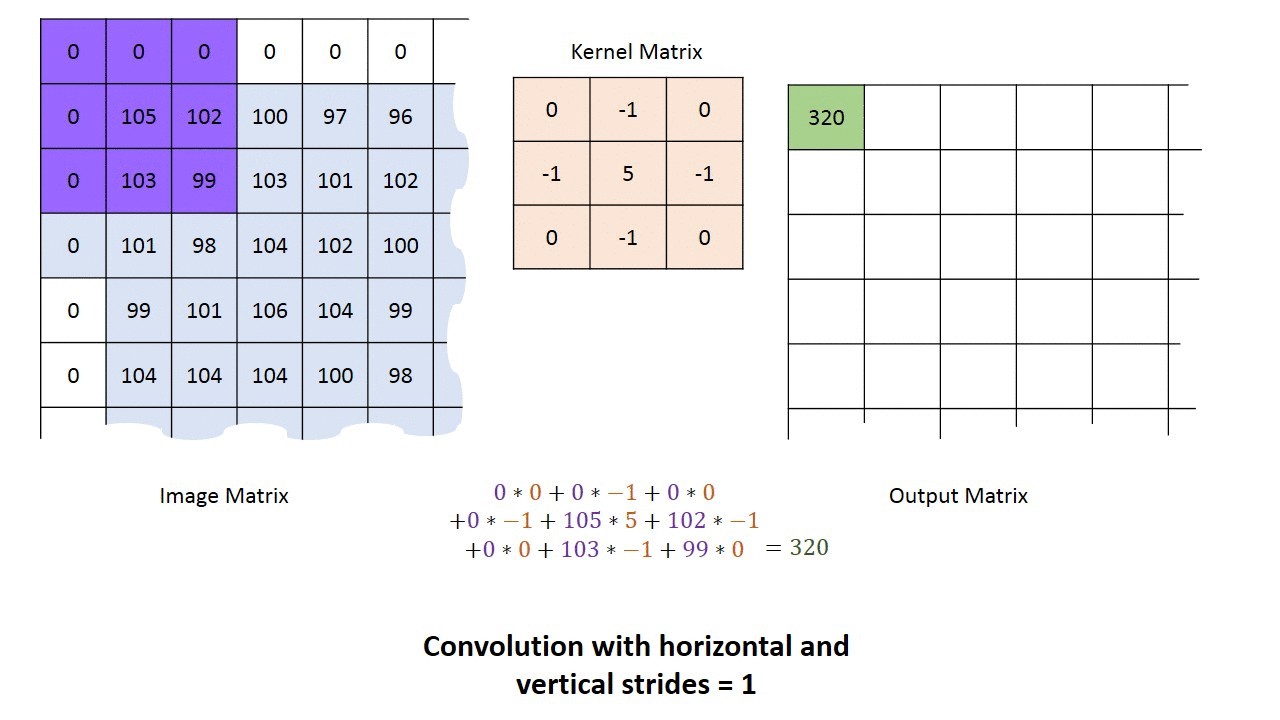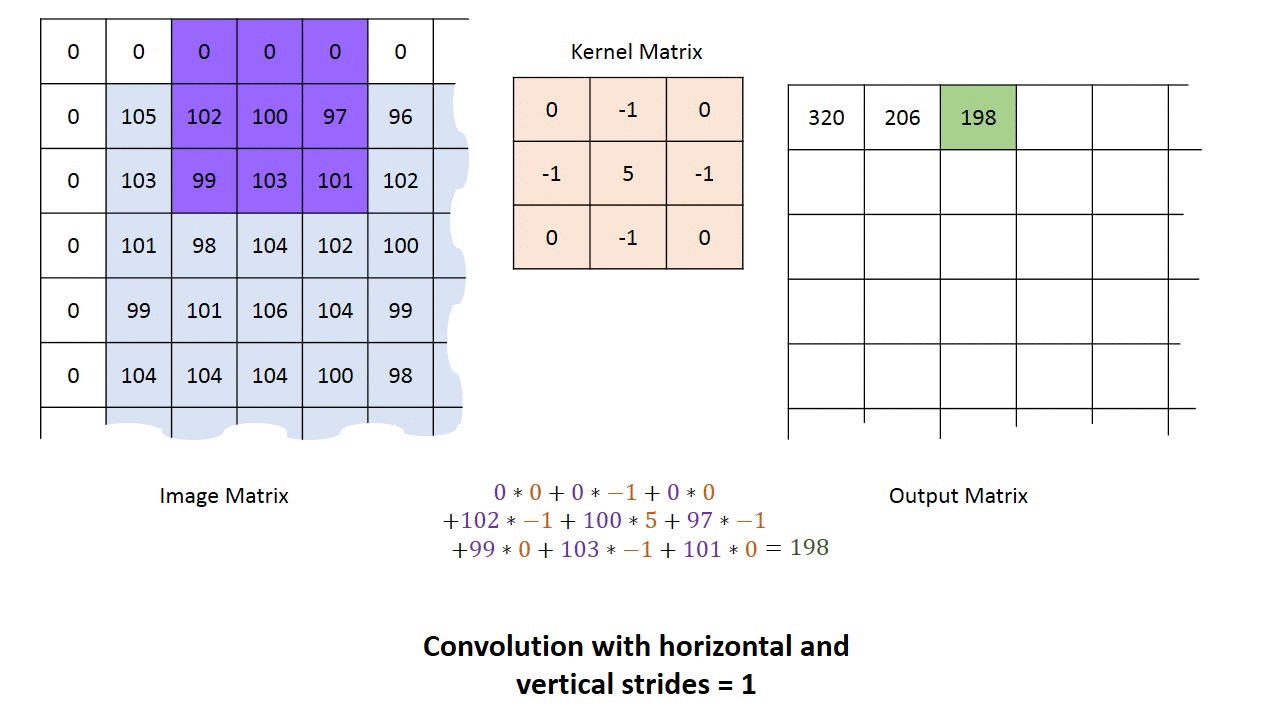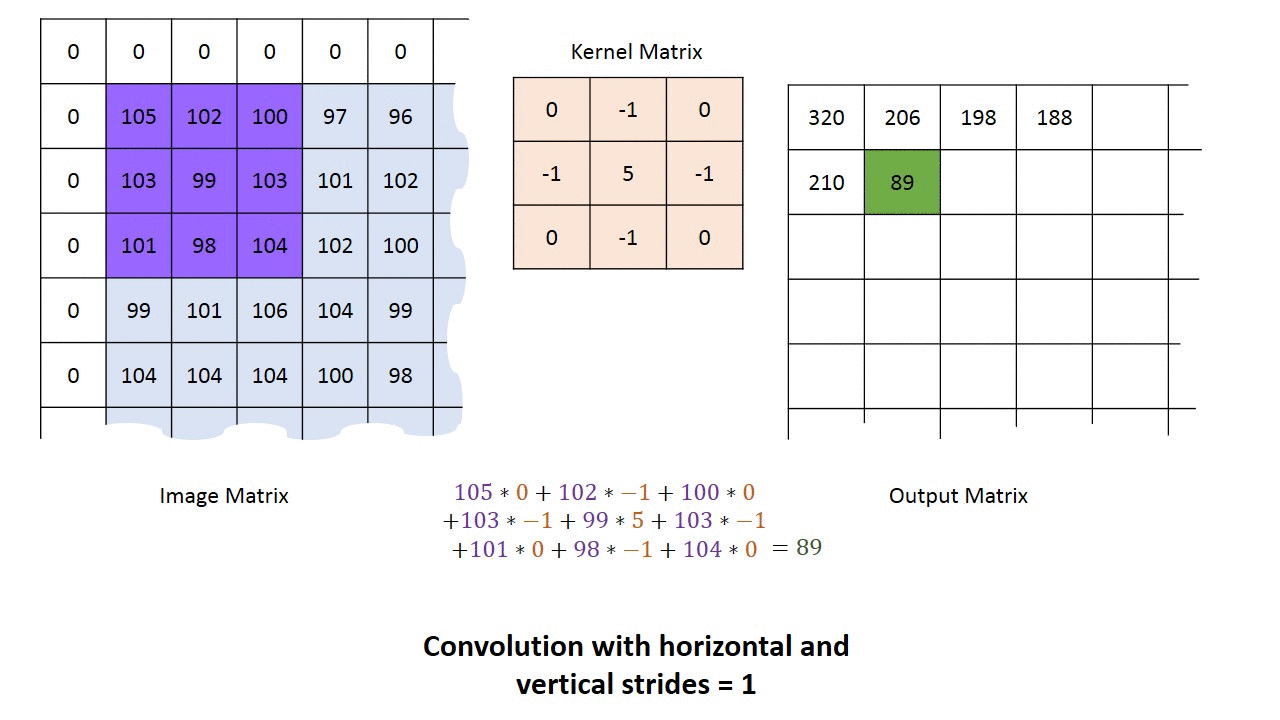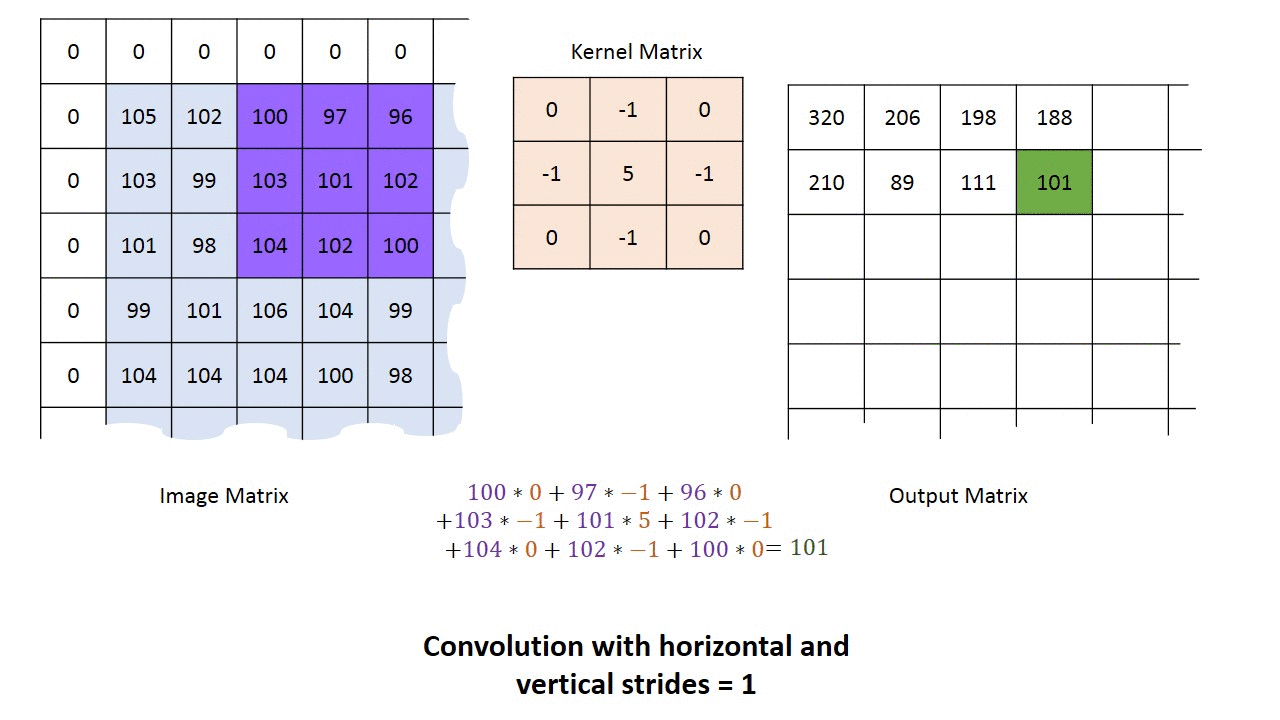
A konvolúciós réteg segítségével primitív mintákat ismerhetünk fel a kép bármely részén, majd ezek alapján újabb konvolúciós rétegek már komplexebb mintákat találhatnak meg. Megfelelő mélység esetén olyan komplex dolgokat is képesek felismerni mint egy macska, vagy épp egy jelzőtábla (pl. egy önvezető autó esetén). Itt ragadnám meg az alkalmat, hogy feloldjak egy látszólagos ellentmondást. Az írás elején azt mondtam, hogy a neurális hálózatokat nem kell programozni, mivel a tanítás során alakul ki a program, ezzel ellentétben az előbbiekben modellekről és a neurális hálózatok programozásáról írtam. Most akkor kell programozni a neurális hálózatokat, vagy nem? Nos, elméletben létezhet olyan neurális hálózat, ami bármilyen programot képes megvalósítani, ugyanakkor ez olyan sok paraméterrel rendelkezne, hogy nem lehetne értelmes időn belül betanítani. Amikor megadjuk a hálózat modelljét vagy topológiáját, akkor tulajdonképpen előhuzalozzuk azt. Ezzel radikálisan csökken a paraméterek száma, a tanításhoz szükséges idő és a szükséges számítási kapacitás. Jó példa erre az előbb említett konvolúciós réteg. Ha adott egy 32x32 pixeles szürkeárnyalatos kép, akkor egy erre felhúzott 32x32-es teljesen összekapcsolt általános háló is képes lenne megtanulni a konvolúciós mintát, de ehhez 32x32 (1024 db) súly értékét kellene meghatározni. Ezzel szemben egy 3x3-as konvolúciós minta esetén csupán 9 db súly meghatározása szükséges, ami jóval egyszerűbb. Ezért vált lehetségessé a konvolúciós réteg által, hogy a gyakorlatban is használható képfelismerő rendszerek jöjjenek létre a neurális hálózatok felhasználásával. A mesterséges intelligencia tehát nem váltja ki a programozók munkáját, csupán máshová helyeződik a fókusz. Míg általános esetben a programozó feladata az algoritmusok megírása, addig a neurális hálók esetén az adatok megfelelő előfeldolgozása és a neurális hálózat topológiájának és modelljének megalkotása a cél. Magát az algoritmust már a tanítás hozza létre. Éppen ezért a neurális hálózatok programozása felfogható egyfajta “metaprogramozásként”.
Most hogy értjük a neurális hálózatok működését, lássuk hogy képezhetőek le ezek tenzor folyamokká. Arról már írtam, hogy a hálózat bemenete és kimenete hogyan képezhető le tenzorok segítségével, arról viszont nem beszéltem, hogy maga a hálózat hogyan írható le tenzorokkal. Ahogyan az előzőekben láthattuk, a neurális hálóknál leggyakrabban használt művelet a bemenetek súlyokkal való beszorzása és összegzése. Ha valaki emlékszik még matek óráról a mátrixok szorzására, beugorhat neki, hogy ott pont ezt kell csinálni. Ha van X db bemenet és Y db neuron, akkor az Y db neuronban képződő összeget megkaphatjuk úgy, hogy egy X elemű vektort (1 dimenziós tenzor) beszorzunk egy Y*X méretű súlyokat tartalmazó mátrixszal (2 dimenziós tenzor), hiszen ennek eredménye pont egy olyan Y elemű vektor, ami a súlyozott összegeket tartalmazza. A mátrix szorzás azért is jó, mert van hozzá szuper jó célhardverünk, mégpedig a gépben lévő videókártya GPU-ja (vagy újabban a TPU, ami direkt MI-re lett kifejlesztve). A GPU-nak pont az az erőssége, hogy sok párhuzamos mátrix szorzást tud elvégezni nagyon gyorsan. Ezért van az, hogy a mesterséges intelligencia alkalmazások esetén sokszor sokkal fontosabb az, hogy milyen GPU van a gépben, mint az, hogy milyen CPU. Az összegképzéshez hasonlóan a kimeneti függvény alkalmazása is egy tenzor transzformáció, ami az Y elemű vektort egy másik Y elemű vektorba képzi le. Ez alapján nézzük meg, hogyan néz ki a második ábrán látható 3 bemenettel, 4 rejtett neuronnal és 2 kimenettel rendelkező neurális háló tenzor transzformációs gráfja. A bemenet egy 3 elemű vektor (1 dimenziós tenzor). Az első transzformáció ezt szorozza be egy 3x4 méretű súlymátrixszal (2 dimenziós tenzor). Az eredmény egy 4 elemű vektor (1 dimenziós tenzor). A következő transzformáció a kimeneti függvény alkalmazása, ami a 4 elemű vektort egy másik 4 elemű vektorba képzi le. Ez a 4 elemű vektor tehát a rejtett réteg kimenete. A következő transzformáció ezt szorozza be egy 4x2 méretű súlymátrixszal, így előállítva az összegeket. Erre alkalmazzuk a kimeneti függvényt, ami egy 2 elemű vektort képez 2 elemű vektorrá, így megadva a hálózat kimenetét. Ezzel kész is a tenzor gráfunk, ami egy 3 elemű, 1 dimenziós tenzort (vektort) képez le egy 2 elemű 1 dimenziós tenzorrá, amihez egy 3x4 és egy 4x2 méretű kétdimenziós paraméter tenzort (mátrixot) használ. A tanítás során ennek a két paraméter mátrixnak az értékei fognak megfelelő módon beállni, ezzel megvalósítva a kívánt működést.
Most, hogy tisztában vagyunk az alapokkal, nézzük hogyan működik mindez a gyakorlatban. Bár a keretrendszer telepítéséhez és a kódok futtatásához némi Python tudás szükséges, úgy gondolom, hogy a főbb részek enélkül is érthetőek.
A lenti kódok kipróbálhatóak a Google Colab-ban is. Érdemes egy új lapfülön megnyitni a notebookot, így olvasás közben rögtön látható is a futás eredménye.
Ha inkább a saját gépünkön futtatnánk a kódokat, úgy elsőként telepítsük a kertrendszert és pár szükséges programkönyvtárat.
pip3 install tensorflow matplotlib numpy
Ha ez megvan, neki is kezdhetünk a neurális háló tanításának. Lássuk is a kódot:
Az első pár sor a CIFAR10 teszt mintahalmaz betöltésére szolgál, amiben felcímkézett képeket találunk a tanításhoz.
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
A train_images és a train_labels tenzorokba kerülnek a tanításhoz használt képek és címkék, míg a test_images és test_labels-be azok, amivel majd kipróbáljuk a neurális hálót.
A CIFAR adatbázis 32x32 pixeles 24bites képeket tartalmaz 3 dimenziós 32x32x3 méretű tenzorok formájában, így minden kép tulajdonképpen 3 db mátrixból áll. Mind a vörös, mind a kék, mind a zöld szín összetevőhöz tartozik egy mátrix ami 0–255-ös tartományban tartalmaz számokat. A következő sor ezt a tenzort normalizálja, hogy az egyes értékek 0–1 tartományba essenek.
train_images, test_images = train_images / 255.0, test_images / 255.0
A következő pár sor a mintahalmazt jeleníti meg a matplotlib segítségével, aminek az eredménye valahogy így néz ki:

Ezután következik a kód igazán lényeges része, a modell felépítése:
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation=’relu’, input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation=’relu’))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation=’relu’))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation=’relu’))
model.add(layers.Dense(10, activation=’softmax’))
model.summary()
Az első sor hozza létre a modellt, ami egy tenzor transzformációs gráf. Jelen esetben egy egyszerű szekvenciális gráf fog készülni, ahol egymást követik a transzformációk.
A model.summary() egy összegzést mutat a modellünkről.
Model: “sequential”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
_________________________________________________________________
flatten (Flatten) (None, 1024) 0
_________________________________________________________________
dense (Dense) (None, 64) 65600
_________________________________________________________________
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
Az első transzformáció egy konvolúció egy 3x3-as szűrővel. A bemenet egy 32x32x3-as tenzor (a kép), a kimeneti függvény pedig a ReLu, ami 0-nál kisebb érték esetén 0-t ad vissza, afelett pedig a bemeneti értéket. Az első 32-es (channel) paraméter azt jelenti, hogy 32 db ilyen konvolúciós szűrő fog létrejönni, melyek mindegyike külön paraméterezhető. A transzformáció kimenete így egy 30x30x32-es dimenziós tenzor, mivel a konvolúciós szűrő a 3 db 32x32-es mátrixot (a képet) 30x30-as mátrixra fogja leképezni és ebből készül 32 db. Ennek megfelelően ez a transzformáció 896 db állítható súly paraméterrel rendelkezik. Ez úgy jön ki, hogy egy 3x3-as szűrő 9 paramétert jelent. Mivel a bemenet 3 mátrixból áll, ezért ez már 27 paraméter. Ehhez jön még egy bemenettől független szám (angolul bias, amit nem tudom hogy lehetne magyarra fordítani), ami így 28-ra növeli a paraméterek számát. Ha pedig megszorozzuk a 28-at a 32 csatornával, kijön a 896 paraméter.
A következő szűrő egy maximumkiválasztás egy 2x2-es sablont használva. Ennek a szűrőnek nincs paramétere és a bemeneti 30x30x32-es tenzort egy 15x15x32-esre képzi le.
A maximumkiválasztást egy újabb konvolúció követi, azt egy újabb maximumkiválasztás, majd még egy konvolúció.
Ezt követi egy Flatten transzformáció, ami “kihajtogatja” a bemeneti tenzort. Így lesz a bemenő 4x4x64-es 3 dimenziós tenzorból egy 1024 elemű vektor (1 dimenziós tenzor).
Az ezt követő Dense transzformáció 64 db neuront hoz létre. A Dense tulajdonképpen a “hagyományos” neurális réteg. Minden neuron bemenetként megkapja az előző réteg kimenetét, így minden neuronnak 1024 bemenete lesz. Ez 1024 súlyt plusz egy bemenettől független bias-t jelent neurononként, így az összes neuron 65600 paraméterrel szabályozható, a kimeneti függvény pedig a már ismertetett ReLu.
Az utolsó réteg egy az előzőhöz hasonló Dense transzformáció, csak ez esetben 10 neuronnal, és softmax kimeneti függvénnyel. A softmax lényege, hogy a kimeneteket 0–1 tartományba hozza úgy, hogy a kimenetek összege 1 legyen (ezt úgy éri el, hogy a kimenetek exponenciális függvényét darabonként elosztja az összes kimenet exponenciális függvényének összegével). A softmax kimenete tulajdonképpen egy százalékos eloszlás a kimenetek közt, ezért is szeretik osztályozó hálózatok kimeneti függvényeként használni. Az így keletkező 10 elemű vektor tehát azt fogja megmondani, hogy az előre meghatározott 10 kategória közül melyikbe mennyire tartozik bele a bemeneti kép.
Megvan tehát a hálózatunk, ami a 32x32x3 méretű 3 dimenziós tenzorként ábrázolt képeket 10 elemű vektorokra (1 dimenziós tenzor) képzi le, ezzel osztályozva a bemeneti mintát.
A következő lépés a modell tanításának konfigurálása, amit a compile metódussal tudunk megtenni.
model.compile(optimizer=’adam’, loss=’sparse_categorical_crossentropy’, metrics=[‘accuracy’])
Mivel ez csak egy alapozó írás, most nem nagyon részletezném, hogy melyik paraméter mit jelent. Elég annyit tudni, hogy az optimalizáláshoz (a potméterek beállításához) az ADAM algoritmust fogjuk használni, a hibát pedig a sparse_categorical_crossentropy függvénnyel mérjük, ami azt mondja meg, hogy mennyire jó az osztályozás.
A konfigurálást követően jöhet a tanítás, amire a fit metódus szolgál.
history = model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
A metódus első két paramétere a tanító minta és a címkék. Ez az amit be szeretnénk tanítani a hálózatnak. A következő (epochs) paraméter azt mondja meg, hogy hány iterációban történjen a tanítás. Végül a validation_data az a tesztadat készlet amivel egy tanítási fázis után tesztelhetjük a hálózatunk hatékonyságát. A tanítás végeztével kapunk egy history-t amit a matplotlibbel megjelenítve láthatjuk hogyan javult a hálózat hatékonysága az egyes tanítási fázisok alatt.

Az ábrán a vonalak szépen mutatják hogyan javult a hálózat hatékonysága az egyes tanítási ciklusokat követően.
A kód végén a save metódussal elmentjük a betanított hálózatunkat, hogy később bármikor elővehessük és használhassuk azt.
model.save(‘my_model.h5’)
Összegezzük tehát mit is építettünk: Létrehoztunk egy neurális hálózatot aminek van 3072 db (32x32x3) bemeneti neuronja és 10 db kimeneti neuronja. Azt szeretnénk elérni, hogy ha a hálózat repülőt “lát”, az 1. neuron aktiválódjon, ha autót, akkor a 2., stb. Ehhez felépítettünk egy hálózatot, ami 122 570 db paraméterrel rendelkezik. Ennyi darab potméter van a fekete dobozunkon amit a tanítás során a tanító algoritmus állítgathat. A 10 lépésből álló tanítást követően a hálózat kb. 70%-os hatásfokkal működik, tehát a teszt minták közül az esetek 70%-ban jól ismeri fel azt, hogy mi van a képen.
Most, hogy ilyen szépen betanítottuk a hálózatunkat, nincs más hátra, mint használni azt. Erre szolgál a következő python kód.
A kód elején a load_model metódussal betöltjük az előzőleg betanított modellt, majd a már megszokott módon betöltjük a CIFAR10-es teszt adathalmazt. Ezt követi két matplotlibes segédfüggvény ami majd az eredmény megjelenítésére fog szolgálni. Ezek működését most ennél jobban nem részletezném. Ami lényeges, az a modell predict függvényének használata.
predictions = model.predict(test_images[i:i+1])
A predict függvény paramétere egy bemeneteket tartalmazó tömb, a kimenete pedig azokat a kimeneteket fogja tartalmazni amit az adott bemenetekre a neurális háló ad. A fenti esetben az i. teszt kép lesz a bemenet, a kimenet pedig az a 10 elemű vektor, amit a hálózat visszaad. Az eredmény grafikusan megjelenítve valahogy így néz ki:

A fenti képen látható, hogy a hálózatunk 91%-os biztonsággal felismerte, hogy a képen egy cica látható. A kutya és a béka neuron még picit aktiválódott, de toronymagasan a cica neuron vezet.
Körülbelül ennyit terveztem írni a tensorflow alapjairól. A cikkből kiderült, hogy mi az a tenzor, mik a neurális hálózatok, és végül össze is raktunk egy hálózatot ami egész magabiztosan ismer fel cicákat képeken. Remélem többen vannak azok, akiknek meghoztam a kedvét a tensorflow-val való kísérletezgetéshez, mint azok, akiknek elvettem. Akit mélyebben érdekel a téma, a neten rengeteg anyagot talál. Persze mindenképp érdemes a Tensorflow hivatalos honlapjáról indulni, illetve azon belül is a Keras API-val indítani, amit a fenti példában mi is használtunk.
Akit mélyebben érdekel, hogy hogyan működik a neurális hálók tanítása, az olvashat róla a Tensorflow alapozó 2. részében.