Tensorflow alapozó 3.
Tensorflow alapozó 3.
(autoencoderek, word2vec és embedding avagy dimenzió redukció neurális hálókkal)
Amikor először hallottam a word2vec-ről valami egészen misztikus dolognak tűnt, hiszen úgy volt képes szavakat vektorokká leképezni, hogy azok információt hordoztak magukban a szó jelentésével kapcsolatban. Tehát az alma vektorának és a körte vektorának távolsága kicsi, míg az alma és az autó távolsága nagy. Még olyan egyszerűbb matematikai műveleteket is lehet végezni a vektorokkal, hogy a “király” szó vektorából kivonjuk a “férfi” szó vektorát, majd hozzáadjuk a “nő” szó vektorát, így megkaptuk a “királynő” szó vektorát. Az az érzése támad az embernek, mintha ez a valami tényleg értené valamilyen szinten a világot, hisz tudja, hogy a királynő a király női változata, ráadásul mindezt a tudás egy sokdimenziós térben elhelyezkedő ponthalmaz reprezentálja. Mikor utánanéztem a word2vec működésének, rá kellett jönnöm, hogy valójában egyszerű dologról van szó, ráadásul az egész szinte adja magát. Így a misztikumát ugyan elvesztette a word2vec, de zsenialitása szemernyit sem kopott.
Neurális hálók esetén gyakori feladat, hogy bizonyos dolgokat vektorokká kell leképezni, hogy aztán könnyebben, gyorsabban és egyszerűbben végezhessünk rajtuk műveleteket. Valójában az első részben épített osztályozó hálózat is felfogható vektorleképzésként, hiszen mikor a képeket 10 osztályba soroljuk az eredmény tulajdonképpen egy 10 dimenziós vektor. Ebben az esetben egyszerű a dolgunk, hiszen minden dimenzióhoz adott jelentés társul (mennyire cica, mennyire kutya, mennyire repülő, stb.), a legtöbb esetben viszont nem hordoznak jelentést az egyes dimenziók, egyszerűen csak a dimenziószámot rögzítjük. Például egy arcfelismerő rendszer esetén az arcot egy adott méretű (mondjuk 512 dimenziós) vektorrá konvertáljuk, majd a tárolt mintavektorral összehasonlítva döntjük el, hogy megegyezik-e a két arc. De hogyan képezhetőek ilyen fix dimenziószámú vektorok?
Amikor valamit vektorrá képzünk le az felfogható egyfajta veszteséges tömörítésnek is. Olyan tömörítést kell tehát találnunk ami csak az elfogadható mértékben veszteséges. Erre a feladatra találták ki az autoencodereket.
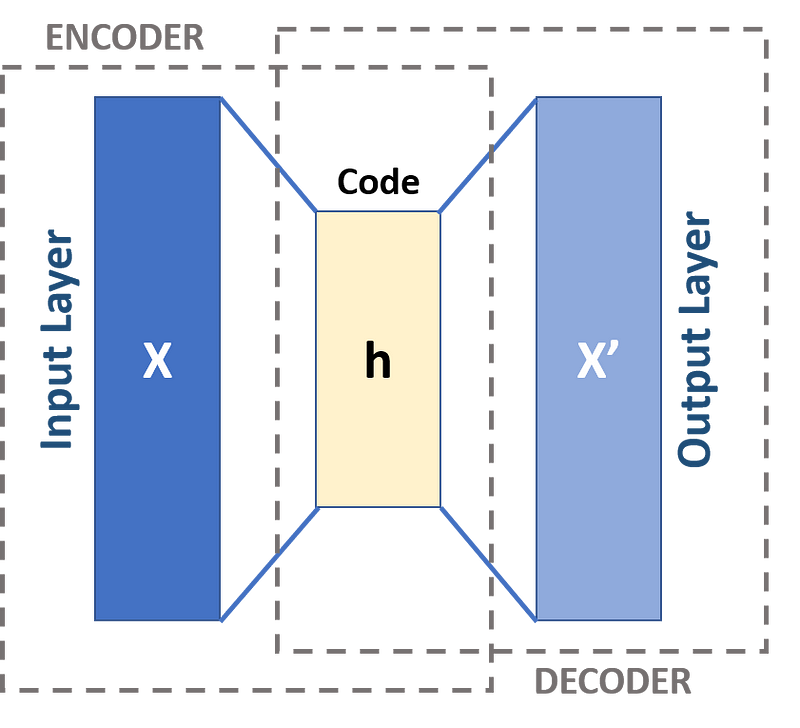
Az autoencoderek két részből állnak. Egy encoderből és egy decoderből. Az encoder az a rész, ami megcsinálja a vektor leképzést, a decoder pedig arra szolgál, hogy a vektor leképzésből visszaállítsa az eredeti adatot. A tömörítéses hasonlatnál maradva tehát készítünk egy hangolható betömörítő és kitömörítő hálózatot, majd addig hangolgatjuk amíg a kitömörítés által adott eredmény csak a megengedett mértékben tér el a bemenettől. Ennyire egyszerű az egész. Ha megvan a kellően jó tömörítés a decodert el is dobhatjuk, az encodert pedig felhasználhatjuk más hálózatokban. A tanítást persze lehet cifrázni például negatív minták alkalmazásával. Egy arcfelismerő hálózat esetén nem csak az lényeges, hogy a rendszer csak kellő mértékben legyen veszteséges, hanem az is, hogy egy arcot ne ismerjen fel másik arcként. Két különböző arc vektorainak tehát megfelelő távolságban kell lenniük egymástól. Nézzünk is gyorsan egy mintát az autoencoderek használatára. Egy 14 szavas szótárat fogunk leképezni 3 dimenziós vektorokká Tensorflow segítségével.
A kód elején definiáljuk a 14 szavas szótárat, pár konstanst és a to_one_hot függvényt, ami a szavakat “one hot” vektorokká alakítja. Ezek olyan vektorok, ahol minden érték 0, csak egyetlen helyen van 1-es. Jelen esetben a “one hot” vektoraink 14 dimenziósak lesznek (ekkora a szótár), és az első szó esetén az 1. helyen áll 1-es, a második szó esetén a 2. helyen áll 1-es, stb. A 14. sorban a shuffle metódussal összekeverjük a vektorokat, így a tanítási mintánk valahogy így fog kinézni:
tf.Tensor(
[[1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]], shape=(14, 14), dtype=float32)
Maga a neurális háló egészen egyszerű. Mindössze 2 rétegből áll. Az első réteg az encoder, ami egy teljesen összekapcsolt Dense réteg átviteli függvény és bias nélkül, tehát valójában itt csak egy sima szorzás történik a súlymátrixszal. A rétegnek 3 kimenete van mivel 3D-s vektorokat szeretnénk kapni a kódolás végén. A réteg súlymátrixa tehát 3x14-es.
model.add(layers.Dense(3, activation='linear', input_shape=(dict_len,), use_bias=False))
A második réteg a decoder, ami ugyancsak egy teljesen összekapcsolt Dense réteg, aminek 3 bemenete és 14 kimenete van. Itt a kimeneti függvény az első részben megismert softmax, amit osztályozó hálóknál szoktunk használni. Valójában itt is egyfajta osztályozásról van szó, hiszen minden szónak egy osztály felel meg.
model.add(layers.Dense(dict_len, activation='softmax'))
A modell tanításánál az osztályozásoknál szokásos categorical_crossentropy hibafüggvényt fogjuk használni.
model.compile(optimizer='adam', loss='categorical_crossentropy')
Végül jöhet a tanítás 2000 ciklusban. Ennyi elegendő ahhoz, hogy megtaláljuk a 3D-s vektorokat.
model.fit(train_data, train_data, epochs=2000, verbose=0)
Ahogy látható, a tanítás bemenete és kimenete egyaránt a train_data, mivel a cél, hogy a dekódolás után a bemeneti vektort kapjuk vissza. A tanítás végeztével a predict függvény által adott indexek jó esetben megegyeznek a bemeneti indexekkel (sikerült a bemenetet saját magára leképezni).
tf.Tensor([ 0 10 8 11 4 2 3 7 9 1 12 13 6 5], shape=(14,), dtype=int64)
tf.Tensor([ 0 10 8 11 4 2 3 7 9 1 12 13 6 5], shape=(14,), dtype=int64)
Persze ez esetben nekünk nem a hálózat kimenete az érdekes, hanem az első réteg súlymátrixsza, ami valahogy így néz majd ki.
array([[ 1.3063056 , 1.7305588 , -0.2699419 ],
[-0.89637613, -2.263997 , -2.460185 ],
[ 1.3254083 , 0.20771885, 1.8607068 ],
[-1.1201528 , -0.79722226, 2.4123664 ],
[-0.1385253 , -2.3953307 , 0.49405864],
[-1.1062597 , 1.5653315 , 1.733906 ],
[-1.5009217 , 2.517614 , -1.2985629 ],
[ 1.8398327 , -0.9083853 , -0.38720697],
[ 1.1028037 , 1.0116827 , -2.245019 ],
[-1.7471856 , 0.23885375, -2.1513062 ],
[ 1.7920303 , -1.8545195 , 1.8756298 ],
[ 2.405476 , 2.3393812 , 2.088418 ],
[-2.1129463 , -1.6200206 , -0.38237098],
[ 1.6532408 , -1.7920396 , -2.3582103 ]], dtype=float32)>]
A mátrix minden egyes sora egy 3D-s vektor, hiszen ha a mátrixot megszorozzuk az adott szó one hot vektorával, pont a szó indexének megfelelő sort kapjuk eredményként.
Ezzel kész is életünk első autoencodere. Persze a legtöbb esetben bonyolultabb az encoder és a decoder rész, és ha csupán szavak kódolása a cél, akkor is lényegesen nagyobb a szótár. Ez persze mind szép és jó, de hogyan képes egy ilyen vektor leképzés olyan misztikus tulajdonságokat felmutatni amilyenekről a cikk elején beszéltem?
Nos, a word2vec esetén van egy kis csavar a dologban. Ott ugyanis nem csak szavakat rendelnek saját magukhoz a vektorizálás folyamán, hanem a szót a hozzá kapcsolódó szavakhoz rendelik. A word2vec esetén tehát a bemenet a királynő szó, az elvárt kimenet pedig a király és a nő szó. Ráadásul a tanítási mintát sem manuálisan válogatják össze, egyszerűen fognak egy nagy szöveghalmazt és az adott szó környezetéből szedik össze, hogy mit rendeljenek hozzá. Ha elég nagy és átfogó a szöveg, úgy pusztán statisztikai alapon az egymáshoz tartalmilag kapcsolódó szavak közeledni fognak egymáshoz, míg a nem kapcsolódóak távolodnak, így tesznek szert a szavakból képzett vektorok olyan misztikus tulajdonságokra, amilyeneket az írás elején említettem.
Akit mélyebben érdekel a dolog működése, annak ajánlom Xin Rong fél órás előadását a témában:
Ha egy neurális háló építésekor szavak vektorokká történő leképzésére lenne szükség, akkor érdemes tudni, hogy létezik egy Embedding nevű réteg, ami bemenetként szó indexeket vár, így nincs szükség a one hot kódolásra. Ennek bemutatására a Tensorflow word embedding tutorial alapján készíteni fogunk egy hálózatot, ami IMDB commenteket osztályoz aszerint, hogy pozitívak, vagy negatívak. Hasonló lesz tehát a hálózat, mint a word2vec esetén, csak itt nem hasonló szavakat fogunk a szavakhoz rendelni, hanem érzelmi töltetet. A várakozás az, hogy az így kialakuló vektor leképzés olyan lesz, ahol a pozitív töltetű szavak közel vannak egymáshoz, ahogyan a negatív töltetű szavak is, a pozitív és negatív szavak közti távolság viszont nagy. Lássuk a kódot!
A kód elején beolvassuk az IMDB commenteket tartalmazó mintahalmazt. A tanító és teszt adatok a train_data és test_data változókba kerülnek, míg a vonatkozó metaadat az info változóba. Az info tartalmazza a 8185 szavas szótárat, amire a train_data és a test_data hivatkozik. Maga az adathalmaz egy lista, amiben minden comment egy szavak indexeit tartalmazó újabb lista. Emellett minden commenthez tartozik egy 1-es vagy 0-s címke, attól függően, hogy a comment pozitív, vagy negatív hangvételű. A beolvasást követő pár sor 10-es csomagokba (batch) szervezi a commenteket, és egységes formára hozza őket.
padded_shapes = ([None],())
train_batches = train_data.padded_batch(10, padded_shapes = padded_shapes)
test_batches = test_data.padded_batch(10, padded_shapes = padded_shapes)
Minden batch egy mátrix, ami 10 sorral rendelkezik, a hossza pedig megegyezik a leghosszabb comment szavainak számával. A rövidebb commentek esetén a fennmaradó helyeket 0-val töltjük fel (padding). Az eredmény valahogy így néz ki:
(10, 855)
[[ 249 4 277 … 5418 8029 7975]
[2080 4956 90 … 0 0 0]
[ 12 284 14 … 0 0 0]
…
[ 12 604 1694 … 0 0 0]
[ 133 67 1011 … 0 0 0]
[ 62 9 1 … 0 0 0]]
[1 1 1 1 1 1 0 1 1 0]
Az első sorban látszik a mátrix dimenziója. Az első batch esetén ez 10x855, mivel a leghosszabb comment (pont az első) 855 szó hosszú. Ezt követi a mátrix rövidített képe. Az utolsó sor az elvárt kimeneteket tartalmazó vektor 10 elemmel, ami az egyes commentek esetén megadja, hogy a comment pozitív, vagy negatív. Ilyen csomagokból áll a tanító minta.
model = models.Sequential([
layers.Embedding(vocab_size, 16),
layers.GlobalAveragePooling1D(),
layers.Dense(1, activation=’sigmoid’)
])
Maga a modell 3 rétegből épül fel. Az első a már említett Embedding réteg, ami a szavakat képzi le 16 dimenziós vektorokká. A tanítás célja, hogy minden szóhoz létrejöjjön egy ilyen vektor, ráadásul olyan módon, hogy a pozitív töltetű szavak vektorainak távolsága kicsi legyen, míg a negatív szavak kerüljenek ezektől távol. A hálózat második rétege a GlobalAvaragePooling1D, ami az egyes vektorok átlagát képzi. Tehát első körben az embedding 16 dimenziós vektorokat képez az egyes commentek szavaiból, majd a GlobalAvaragePooling1D-nek köszönhetően egyetlen átlagvektor keletkezik, ami nagyjából jellemző a commentre. Az utolsó réteg egy sima 16 bemenetű neuron sigmoid kimenettel, ami a vektorból bináris kimenetet képez. Ennyi lenne tehát a hálózat, amivel a betanítjuk a vektor leképzést végző Embedding réteget.
Model: “sequential”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 130960
_________________________________________________________________
global_average_pooling1d (Gl (None, 16) 0
_________________________________________________________________
dense (Dense) (None, 1) 17
=================================================================
Total params: 130,977
Trainable params: 130,977
Non-trainable params: 0
_________________________________________________________________
Ha megnézzük a sumary-t, láthatjuk, hogy az embedding réteg 130960 paraméterrel rendelkezik, mivel a súlymátrix 8185x16-os, hiszen 8185 elemű a szótárunk és 16 dimenziós vektorokat szeretnénk kapni. A global_avarage_pooling-nak nincs paramétere, az egyetlen kimeneti neuronunk pedig 16 bemenettel rendelkezik, plusz egy bias, így jön ki a 17 paraméter.
A tanításhoz a szokásos adam optimalizálót használjuk, hibafüggvénynek pedig a binary_crossentropy-t. Tanítás után a vektorokat az embedding réteg súlyainak lekérdezésével kaphatjuk meg.
weights = model.layers[0].get_weights()[0]
Persze egy 8185x16-os mátrixot elég nehéz áttekinteni és bármiféle jelentést társítani hozzá. Szerencsére létezik egy Embedding Projector nevű cucc, ami képes arra, hogy a kapott vektorokat 3D-ben megjelenítse. Az utolsó pár sor arra szolgál, hogy a vektorainkat a projector által olvasható tsv formátumba mentse. Két fájl fog keletkezni. Az első a vecs.tsv ami a vektorokat tartalmazza, a második a meta.tsv, ami a vektorokhoz tartozó szavakat tartalmazza. A fájlokat az Embedding Projector bal oldali Load gombjával tudjuk betölteni. Ha ezzel megvagyunk, a jobb oldalon keressünk rá mondjuk a ‘fun’ szóra. Alul rögtön meg is jelenik a vektortávolság alapján a 100 legközelebbi szó. Szépen látszik, hogy mind pozitív töltetű. Olyanok mint ‘beautiful’, ‘amazing’, stb. Próbáljunk valami negatív töltetű szót, pl. ‘boring’. Erre szűrve a közeli szavak ‘stupid’, ‘garbage’ és hasonlók, tehát a hálózatunk tényleg olyan vektor leképzést generált, amit vártunk tőle. Érdemes kipróbálni az Embedding Projector alap szettjeit is. Ott van például a cikk elején említett Word2Vec, ahol rákeresve a ‘queen’ szóra olyan közeli szavakat kapunk, mint ‘king’ vagy ‘princess’.
Körülbelül ennyit szerettem volna írni az autoencoderekről és az embeddingről. Persze a témát még nagyon sokféleképpen lehetne ragozni, de úgy gondolom, hogy a fentiek elég alapot biztosítanak arra, hogy akit mélyebben érdekelnek a dolgok, az utána tudjon nézni.
Ha tetszett az írás, és még nem tetted, olvasd el az előző két részt is:
A következő részt pedig itt találod: