Tensorflow alapozó 6.
Tensorflow alapozó 6.
GAN-ok, avagy hogyan generáljunk cicákat neurális hálóval
A generatív hálózatok egy igen izgalmas területe a machine learningnek. Ezek azok a neurális hálók, amik tájképeket, festményeket, vagy éppen emberi arcokat képesek létrehozni.

A fenti képen látható lánnyal például biztos nem fogunk összefutni az utcán, hiszen őt is egy neurális háló generálta. A generatív hálózatok egyik legnépszerűbb formája a Generative Adversarial Network, vagy röviden GAN. Az architektúra lényege, hogy két neurális hálózatot versenyeztetünk egymással. Az egyik hálózat a generátor, ami egy feature vectorból generál képet. Emlékezzünk kicsit vissza az autoencoderes részre. Itt ugye az volt a cél, hogy valamiből (szavakból, képekből, stb.) egy vektor leképzést készítsünk. Ezt úgy értük el, hogy egy encoderrel elóállítottuk a feature vectort, majd egy decoderrel vissza, és ha a visszaállított forma megfelelő volt, a decodert egyszerűen eldobtuk. Így maradt egy hálózatunk, ami képes volt a feature vector előállítására. Nos, a generátor tulajdonképpen az egésznek a decoder része, ami a feature vectorból képes képeket készíteni. Véletlenszerű új képeket pedig úgy generálhatunk, hogy véletlenszerűen generált feature vectorokkal etetjük a generátort. A kérdés már csak az, hogy hogyan készíthetünk ilyen generátort? Itt jön a képbe a másik hálózat, aki a kritikus (discriminator). A kritikus egyetlen célj, hogy az adott képről megmondja, hogy valódi, vagy generált. Úgy is szokták ezt magarázni, hogy az egyik hálózat a “képhamisító”, míg a másik a szakértő. A szakértő célja, hogy kiszúrja a hamisítványokat, míg a hamisító célja, hogy átverje a szekértőt. Ők tehát azok, akik egymással versenyeznek. A tanítás maga úgy történik, hogy a szakértőnek mutatunk pár valódi képet (pl. arcokat), majd pár olyan képet amit a generator készített véletlenszerű feature vectorokból. A minták meg vannak cimkézve valódi/hamis címkékkel, így a hagyományos módon elvégezhető a tanítás. Ezt követően a generatort tanítjuk be véletlenszerű feature vectorokkal, hogy olyan képeket generáljon, amire a szakértő azt mondja, hogy valódi. A tantást követően fejlődik a generator, amivel a szakértőt tanítjuk, így ő is fejlődik, amivel tovább fejlődik a generator, stb.
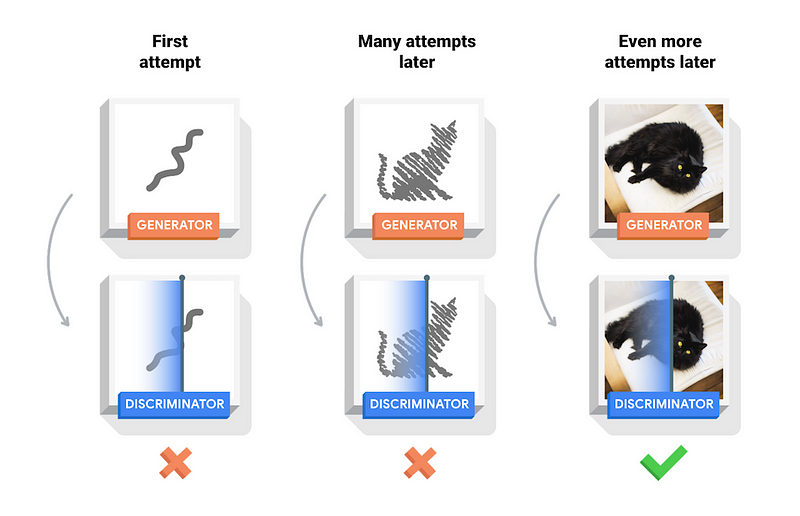
Így versenyez egymással a két hálózat, és így születik meg a folyamat végén a tökéletes generator, ami aztán szinte hibátlan festményeket, cicákat, vagy éppen emberi arcokat generál pusztán véletlen zajból. Ennyi elég is az elméletből, lássuk a kódot! Mivel cicákat generálni elég számításigényes, ezért kézzel írott számjegyeket fogunk generálni.
Aki ki is próbálná, az itt elérheti Colab notebook formában. Ha futtatjuk a kódot, mindenképp érdemes GPU-ra váltani a Runtime Type-ot a gyors futtatás érdekében.
A kód elején betöltjük a MINST adathalmazt, ami 60 000 felcimkézett, kézzel írt számjegyet tartalmaz. Mivel nekünk most csak a képek fognak kelleni, a cimkéket eldobjuk. A MINST adathalmaz 28x28-as szürkeárnyalatos képeket tartalmaz, így az elemek 28x28x1-es tenzorok. A pixelek árnyalata 0–255-ig terjedhet. Ezt képezzük le a [-1,1] tartományra.
Model: “sequential”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 14, 14, 64) 1664
_________________________________________________________________
leaky_re_lu (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
dropout (Dropout) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 7, 7, 128) 204928
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 7, 7, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 6272) 0
_________________________________________________________________
dense (Dense) (None, 1) 6273
=================================================================
Total params: 212,865
Trainable params: 212,865
Non-trainable params: 0
_________________________________________________________________
A neurális hálók közül a kritikus (discriminator) az egyszerűbb. Ez egy konvolúciós háló. Hasonló, mint amit az első részben építettünk a CIFAR-10-es képek felismerésére, csak itt 10 helyett egyetlen kiment van, ami 0–1-ig terjedő skálán mutatja a bemeneti kép valódiságát. Ami még újdonság, az a MaxPool réteg helyett használt LeakyReLu és a Dropout réteg. A LeakyReLu abban különbözik a sima ReLu kimeneti függvénytől, hogy a 0-nál kisebb értékek esetén 0 helyett a bemenet alpha szorosát adja vissza (ami alap esetben 0.3). Ezért is hívják “szivárgó” (leaky) ReLu-nak, mert a 0-nál kisebb értékeket nem vágja le, valamennyire ezek is átszivárognak a kimeneti függvényen. A Dropout a belementek bizonyos százalékát véletlenszerűen eldobja (0-ra állítja). Ezt a réteget azért szokták használni, hogy a hálózat ne tanulja meg teljesen pontosan a mintákat (overfitting), ehelyett próbálja kinyerni a lényeges komponenseket. A hálózat végén a szokásos Flatten és egy teljesen csatolt Dense réteg található.
Model: “sequential_1”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 12544) 1254400
_________________________________________________________________
batch_normalization (BatchNo (None, 12544) 50176
_________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 12544) 0
_________________________________________________________________
reshape (Reshape) (None, 7, 7, 256) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 7, 7, 128) 819200
_________________________________________________________________
batch_normalization_1 (Batch (None, 7, 7, 128) 512
_________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 14, 14, 64) 204800
_________________________________________________________________
batch_normalization_2 (Batch (None, 14, 14, 64) 256
_________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_transpose_2 (Conv2DTr (None, 28, 28, 1) 1600
=================================================================
Total params: 2,330,944
Trainable params: 2,305,472
Non-trainable params: 25,472
_________________________________________________________________
A generátor tulajdonképpen egy fordított konvolúciós háló. Az első réteg egy 12544 neuronból álló teljesen csatolt Dense réteg. Mivel egy 100 elemű véletlenszerű feature vectorból indulunk ki, ezért minden neuronnak 100 bemenete lesz. Ebben a rétegben áll elő az a 12544 érték, amit a Reshape réteg 7x7x256-os tenzorrá konvertál és amit a hálózat 28x28x1-es kimeneti tenzorrá fog felskálázni. Ehhez a Conv2DTranspose réteget használja, ami tulajdonképpen egy fordított konvolúció. Míg a konvolúció egy tenzort kisebb tenzorra képez le a fontos jellemzők kinyerésével, addig a Conv2DTranspose a jellemzők tenzorából generál egy nagyobb tenzort.
discriminator.trainable = False
gan = models.Sequential([
generator,
discriminator
])
Van egy harmadik hálózatunk is gan néven, aminek első rétege a generator, a második a discriminator. Erre a hálózatra a tanításhoz van szükség. A hálózat létrehozása előtt a discriminator trainable tulajdonságát False-ra állítjuk. Ettől a discriminator maga még tanítható, de mikor a gan-t tanítjuk, a rendszer konstansnak veszi, és csak a generator súlyait változtatja. A generatort tehát nem közvetlenül, hanem a gan-on keresztül tanítjuk. A gan bemenete a 100 elemű zajvektor, a kimenete pedig egy 0–1-ig terjedő szám, ami azt mondja meg, hogy mennyire valós a generator által előállított kép. Az elvárt kimenet tehát mindig 1 lesz a tanításnál, mivel azt szeretnénk, hogy igazinak tűnjenek a képek. Hogy tisztább legyen, lássuk hogy megy a tanítás:
noise = tf.random.normal([BATCH_SIZE, noise_dim])
fake_images = generator.predict(noise)
real_images_y = np.ones((BATCH_SIZE, 1))
discriminator.train_on_batch(images, real_images_y)
fake_images_y = np.zeros((BATCH_SIZE, 1))
discriminator.train_on_batch(fake_images, fake_images_y)
gan_y = np.ones((BATCH_SIZE, 1))
gan.train_on_batch(noise, gan_y)
Minden lépésben (epoch) generálunk egy BATCH_SIZE méretű zajtenzort, aminek minden eleme egy 100 elemű véletlenszerű feature vector. Ezt nyomjuk keresztül a generatoron, hogy létrejöjjenek a hamis képek. Első körben a discriminatort tanítjuk a valós képekkel. Ezek esetén az elvárt kimenet 1-es (valódi). A következő körben még mindig a discriminatort tanítjuk, csak ezesetben az elvárt kimenet 0 (hamis). Most hogy a discriminatorunk eggyel jobban tud igazi és hamis képeket megkülönböztetni, jöhet a generator tanítása a gan hálózaton keresztül. Ennek bemenete ugyancsak a zajtenzor, az elvárt kimenet pedig 1-es (valódi). Mivel a tanítás a discriminatorra nincs hatással, ezért a generator súlyait fogja úgy módosítani a rendszer, hogy az eredmény minél közelebb legyen az 1-hez. Ha a folyamatot kellően sokszor ismételjük, a generator végül megtanul egészen valósághű képeket generálni.

A fenti animált GIF-en jól látszik, hogyan lesznek a kezdeti véletlen zajból végül kézzel írt számok a tanítási fázisok alatt.
Ha valaki kipróbálja a kódot Colabban GPU-val, az tapasztalhatja, hogy egy epoch kb. 20 másodpercig tart, ami nem kevés. Az erdeti Tensorflow tutorialban található kód esetén ez az érték 10 másodperc. Ez a 2x-es gyorsulás az egyedi tanításnak kösznhető. Úgy gondoltam, hogy a GAN működését jobban meg lehet érteni a fenti train_on_bach függvényt használó kód alapján, ezért használtam ezt a megoldást, ugyanakkor mindenképp érdemes vetni egy pillantást az eredeti megoldásra (ez is elérhető Colabban).
Az egyik lényeges pont, hogy ennél a megoldásnál saját hibafüggvényeket definiálunk.
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
A discriminator_loss függvény visszatérési értéke a discriminator valódi és hamis képekre adott hibájának az összege, míg a generator esetén a hamis képekre adott hibát számoljuk. Mindkét esetben a BinaryCrossentropy hibafüggvényt használjuk, amit az első részből már ismerhetünk.
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
Maga a tanítás egy csomó érdekes megoldást alkalmaz. Ott van például a GradientTape, amiről a második részben volt szó. Ő az, aki a hálózat futtatása közben összeszedi a gradienseket, ami alapján módosíthatjuk a súlyokat. A fenti példában rögtön kettő GradientTape-et is indítunk. Az egyiktől a generatorra vonatkozó gradienseket szedjük össze, a másiktó a discriminatorra. A gradiensek segítségével optimalizáljuk a hálózatokat. Az optimalizáláshoz a jól megszokott Adam-et használjuk. Maga az előre futtatás (forward phase) annyiból áll, hogy a zajtenzor alapján legeneráljuk a hamis képeket. Ezekre lefuttatjuk a discriminatort, majd kiszámoljuk a hibákat.
Ami még érdekesség, az a tf.function decorator. Pythonban a decorator afféle csomagoló függvény. Ha egy függvényt ilyennel látunk el, akkor mikor használjuk, valójában nem a függvényt hívjuk, hanem egy másik függvényt, amit a decorator visszaadott. A tf.function azt csinálja, hogy a dekorált függvényt tensorflow gráffá fordítja. Maga a gráf a natív rétegben jön létre, így mikor meghívjuk a függvényt, a paraméterek közvetlenül a natív réteghez kerülnek, ami végigfuttatja azokat. A tf.function tehát sokkal gyorsabb futtatást tesz lehetővé.
Ezzel a két megoldással, tehát a tf.function és a GradientTape használatával érhető el a fent említett 2x-es gyorsulás.
Körülbelül ennyit szerettem volna írni a GAN-okról. Aki esetleg hiányolja a címben említett cicákat, az itt találhat egy kódot cicák generálására. A fejlesztő szerint a képen látható cicák 20 órányi tanításba és 170$-ba kerültek neki. Erre gondoltam, mikor azt írtam, hogy cicákat generálni számításigényes feladat.
A GAN-oknak nagyon sok továbbfejlesztett változata létezik. A https://www.thispersondoesnotexist.com/ például StyleGAN-t használ, de ugyancsak erre a technológiára épül a Pix2pix amivel béna kis szabadkezi rajzokat alakíthatunk műalkotássá. Ezen kívül használják őket DeepFake videók létrehozásánál, és még megannyi helyen. Akit mélyebben érdekel a téma, az rengeteg anyagot találhat neten. Remélem ez a kis írás jó alapot biztosít majd a további kutatáshoz.
Ha tetszett az írás, olvasd el a korábbi részeket is:
(autoencoderek, word2vec és embedding avagy dimenzió redukció neurális hálókkal)medium.com
A következő részt pedig itt találod: